----
XLNet против BERT
// Лучшие публикации за сутки
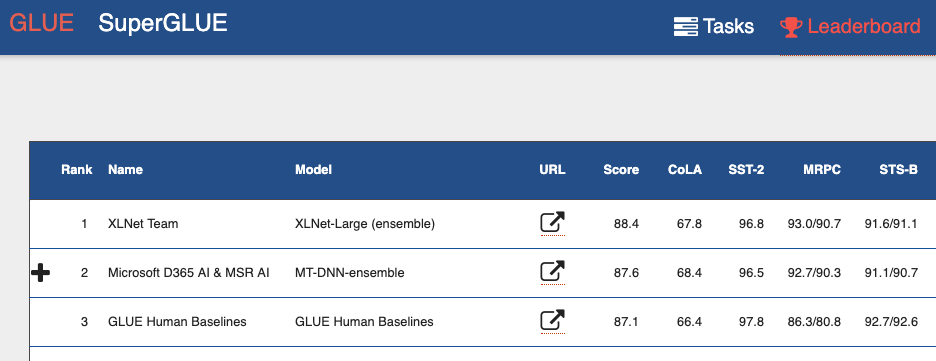
В конце июня коллектив из Carnegie Mellon University показал нам XLNet, сразу выложив публикацию, код и готовую модель (XLNet-Large, Cased: 24-layer, 1024-hidden, 16-heads). Это предобученная модель для решения разных задач обработки естественного языка.
В публикации они сразу же обозначили сравнение своей модели с гугловым BERT-ом. Они пишут, что XLNet превосходит BERT в большом количестве задач. И показывает в 18 задачах state-of-the-art результаты.
Читать дальше →
----
Read in my feedly
Sent from my iPad
Комментариев нет:
Отправить комментарий